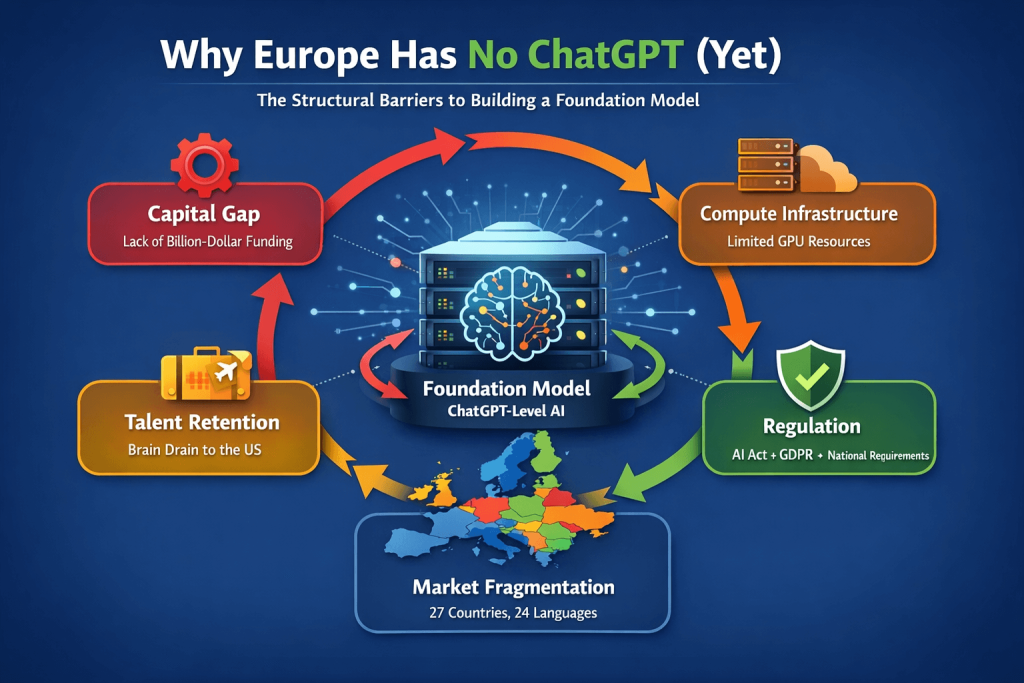
Europa heeft geen eigen ChatGPT. En dit is niet te wijten aan een gebrek aan talent of ambitie. Het is het resultaat van structurele omstandigheden die zich in de loop van vele jaren hebben ontwikkeld - en die niet kunnen worden opgelost door één enkel financieringsprogramma of politieke toespraak. Wie wil begrijpen waarom Europese AI-alternatieven nauwelijks zichtbaar zijn op de consumentenmarkt, moet kijken naar vijf onderling samenhangende factoren.
Wat “Alternatief” hier eigenlijk betekent
Voordat we de oorzaken bespreken, helpt het om de terminologie te verduidelijken. Veel tools promoten zichzelf met labels als “Europese AI” of “AI Made in Germany”. De meeste werken op de applicatielaag - ze vertrouwen op backendmodellen van OpenAI, Anthropic of Google en voegen hun eigen interface, privacyfuncties of branchespecifieke functionaliteit toe.
Dat is op zich niet slecht. Maar het is fundamenteel anders dan een basismodel: een groot taalmodel dat vanaf de grond is opgebouwd met eigen gegevens, infrastructuur en onderzoeksteams. ChatGPT is gebaseerd op GPT-4o, zo'n basismodel. Wanneer in dit artikel wordt verwezen naar “echte alternatieven”, wordt dit niveau bedoeld - niet wrappers met een EU-vlag.
Kapitaal: Het grootste structurele nadeel
Het ontwikkelen van een concurrerend stichtingsmodel vereist middelen op een schaal die Europese financieringsstructuren zelden ondersteunen. Sinds 2023 heeft OpenAI meerdere financieringsrondes van meerdere miljarden dollars achter de rug. Google, Meta en Microsoft investeren jaarlijks tientallen miljarden in AI-infrastructuur en -onderzoek.
Het Europese VC-landschap werkt op een andere schaal. Individuele financieringsrondes van honderden miljoenen zijn al uitzonderlijk. Mistral AI heeft dit aangetoond met zijn financiering - en blijft eerder uitzondering dan regel. Bovendien zijn Europese investeerders eerder risicomijdend. De bereidheid om honderden miljoenen te investeren in een bedrijf dat er jaren over kan doen om winstgevend te worden, is aanzienlijk groter in de Verenigde Staten.
Het resultaat is een vicieuze cirkel. Zonder enorme financiering, geen training van wereldklasse. Zonder een model van wereldklasse, geen overtuigend product. Zonder een overtuigend product, geen gebruikers - en dus geen argument voor de volgende financieringsronde.
Computerkracht en cloudinfrastructuur
Het trainen van foundationmodellen betekent dat duizenden GPU's weken of maanden parallel moeten draaien. Deze rekencapaciteit wordt bijna volledig beheerd door Amerikaanse hyperscalers. AWS, Microsoft Azure en Google cloud. Europese cloudproviders zoals OVHcloud of IONOS zijn sterk in traditionele hosting, maar bieden geen vergelijkbare GPU-infrastructuur voor AI-training.
De EU heeft dit erkend en programma's zoals EuroHPC gelanceerd om Europese supercomputercapaciteit op te bouwen. Deze initiatieven zijn een begin. Ze zijn echter vooral gericht op het wetenschappelijke domein en voorzien niet in de commerciële vraag die nodig is om meerdere bedrijven die tegelijkertijd funderingsmodellen maken te ondersteunen. Op dit moment huurt iedereen in Europa die een groot taalmodel wil trainen waarschijnlijk GPU-clusters van een Amerikaanse leverancier.
De talentenmarkt: Sterk onderwijs, zwakke retentie
Europese universiteiten en onderzoeksinstellingen produceren AI-onderzoek van wereldklasse. DeepMind is opgericht in Londen. Yann LeCun studeerde in Parijs. ETH Zürich, TU München, EPFL - de kwaliteit van het onderwijs is internationaal concurrerend.
Het probleem ligt niet in het opleiden van talent, maar in het behouden ervan. Bedrijven in de VS bieden salarissen en aandelenpakketten die Europese werkgevers zelden evenaren. Grotere teams, snellere carrièrepaden en toegang tot infrastructuur die in Europa gewoonweg niet in dezelfde vorm bestaat, versterken deze dynamiek nog. Braindrain is niet nieuw, maar bij AI is het bijzonder uitgesproken omdat de vraag naar specialisten veel groter is dan het aanbod.
Fragmentatie van de markt: 27 landen, geen eengemaakte markt
Een Amerikaanse startup die een Engelstalig product lanceert, bereikt onmiddellijk een markt van meer dan 300 miljoen mensen met een uniform rechtssysteem, taal en bedrijfscultuur. Een Europese startup krijgt te maken met 27 landen met verschillende talen, regels en financieringsmechanismen.
De EU is een interne markt voor goederen. Voor digitale producten - met name AI-toepassingen die onderhevig zijn aan regelgeving - is er slechts sprake van een gedeeltelijke eenwording. Financieringsprogramma's zijn nationaal versnipperd. Aanbestedingsprocessen verlopen volgens verschillende logica's. Zelfs binnen de EU verschillen de vereisten voor gegevensbescherming per nationale toezichthouder. Dit maakt schaalvergroting duurder en trager dan in de VS of China.
| Onderwerp | Verenigde Staten | Europese Unie |
|---|---|---|
| Toegang tot de markt | Eén verenigde markt, meer dan 330 miljoen mensen | 27 landen, gefragmenteerde markt |
| Taal | Eén taal voor één productlancering | 24 officiële talen, lokalisatie vereist |
| Wettelijk kader | Eén federaal systeem, één set regels | 27 nationale interpretaties van EU-wetgeving |
| Financieringslandschap | Rondes van meerdere miljarden dollars komen vaak voor | Rondes boven €500M blijven uitzonderlijk |
| Publieke financiering | Gecentraliseerde federale programma's (DARPA, NSF) | Versnipperd over nationale en EU-programma's |
| Inkoop | Eén federale aanbestedingsprocedure | 27 verschillende systemen voor openbare aanbestedingen |
| Wettelijke last | Lichter, sneller op de markt | AI-wet + GDPR + nationale vereisten |
| Behoud van talent | Hoge salarissen, aandelenpakketten, visumprogramma's | Brain drain naar VS, lager compensatieplafond |
| Cloudinfrastructuur | Hyperscalers met hoofdkantoor in eigen land | Afhankelijk van Amerikaanse hyperscalers voor GPU-toegang |
| Tijd om te schalen | Eén keer lanceren, onmiddellijk schalen | Uitrol per land |
Regelgeving: Belemmering of concurrentievoordeel?
De AI Act, GDPR en verschillende nationale regelgevingen creëren een nalevingskader waar Amerikaanse startups niet in dezelfde mate doorheen hoeven te navigeren. Voor een jong bedrijf met beperkte middelen betekent elke extra wettelijke vereiste minder budget voor productontwikkeling.
Tegelijkertijd is het tegenargument steekhoudend. Regelgeving kan een vertrouwensvoordeel creëren. Bedrijven die aantoonbaar GDPR-compliant werken, hebben in bepaalde sectoren - gezondheidszorg, financiën, openbaar bestuur - een duidelijk voordeel ten opzichte van Amerikaanse aanbieders wier gegevensverwerking slechts gedeeltelijk aan de Europese normen voldoet.
Het eerlijke antwoord is dat regelgeving beide is. Het vertraagt de ontwikkeling van consumentenproducten maar legt een basis voor betrouwbare B2B-toepassingen. Wie verwacht dat Europa een tweede ChatGPT produceert, zal waarschijnlijk teleurgesteld worden. Wie op zoek is naar soevereine AI-oplossingen voor gereguleerde sectoren, zal ze steeds vaker hier vinden.
Wat bestaat: Het Europese AI-landschap (vanaf 2025/2026)
Ondanks structurele nadelen bestaan er Europese bedrijven die hun eigen funderingsmodellen ontwikkelen. Het landschap is beperkt - maar echt.
Mistral AI (Frankrijk) is de bekendste Europese speler. Het bedrijf heeft verschillende eigen modellen uitgebracht, waaronder open-source varianten, en positioneert zichzelf als een krachtig alternatief voor OpenAI met een focus op API-toegang voor ontwikkelaars en bedrijven. Mistral heeft Europa's grootste AI-financieringsronde binnengehaald en werkt samen met grote cloudproviders. Het consumentenproduct (Le Chat) bestaat, maar is niet de strategische focus.
Aleph Alpha (Duitsland) heeft zich bewust gespecialiseerd in de B2B- en overheidsmarkt. In plaats van te concurreren met ChatGPT in de consumentenmarkt, richt het bedrijf zich op use cases in gereguleerde sectoren met eigen hosting en Europese datasoevereiniteit. De strategische herpositionering van het bedrijf in de afgelopen jaren illustreert een bredere trend: succes voor Europese providers zal eerder te danken zijn aan specialisatie dan aan concurrentie op de massamarkt.
Daarnaast bestaan er kleinere initiatieven en open-source projecten, bijvoorbeeld van onderzoeksinstellingen of door de EU gefinancierde consortia. Deze zijn relevant voor specifieke gebruikssituaties, maar verschijnen niet als consumentgerichte producten.
Een uitgebreid overzicht van Europese AI-alternatieven en gespecialiseerde tools vind je hier:
Heeft Europa wel een eigen ChatGPT nodig?
Focus op het opbouwen van een één-op-één consumentenclone die wordt gedreven door politieke verhalen zoals digitale soevereiniteit of strategische onafhankelijkheid.
Focus op gegevensverwerking, contractuele controle, afhankelijkheidsbeheer en op risico's gebaseerde architectuurbeslissingen.
Deze vraag wordt vaak reflexmatig met ja beantwoord - digitale soevereiniteit, strategische onafhankelijkheid, Europese waarden. De argumenten zijn geldig. Maar ze worden misleidend als ze leiden tot eisen voor een één-op-één ChatGPT-kloon.
De meer strategisch relevante vraag is: waar heeft Europa eigenlijk zijn eigen modellen nodig - en waar volstaat een soevereine toepassingslaag die voortbouwt op bestaande basismodellen? Voor de meeste bedrijfsapplicaties zijn de kritieke factoren waar gegevens worden verwerkt, welke contractuele kaders van toepassing zijn en hoe de afhankelijkheid van individuele leveranciers wordt beperkt. Hiervoor is niet per se een Europees basismodel nodig, maar eerder een goed ontworpen architectuur.
De situatie is anders voor veiligheidskritische toepassingen - defensie, inlichtingendiensten, kritieke infrastructuur. Hier vormt afhankelijkheid van Amerikaanse modellen een reëel risico. Op deze gebieden is digitale soevereiniteit op modelniveau echt relevant. Voor het gemiddelde bedrijfsproces is dat slechts gedeeltelijk het geval.
Wat Europese bedrijven nu kunnen doen
Wachten op een Europese ChatGPT is geen strategie. Vier meer pragmatische benaderingen zijn dat wel:
Gebruik Amerikaanse modellen op een GDPR-conforme manier. Verschillende providers bieden nu Europese hosting- en gegevensverwerkingsovereenkomsten die voldoen aan de GDPR-eisen. OpenAI's EU-hostingopties, Azure OpenAI Service met Europese datacenters en vergelijkbare aanbiedingen van Anthropic en Google maken het mogelijk om krachtige modellen te gebruiken binnen Europese regelgevingskaders.
Evalueer Europese aanbieders voor gespecialiseerde use cases. Bedrijven die actief zijn in gereguleerde sectoren of maximale gegevenssoevereiniteit vereisen, moeten providers zoals Mistral of Aleph Alpha beoordelen. Hun modellen zijn krachtig genoeg voor veel B2B-toepassingen en bieden voordelen op het gebied van compliance en het opstellen van contracten.
Vermijd vendor lock-in. Het AI-landschap evolueert snel. Bedrijven die zich nu volledig aan één leverancier binden, kunnen over twee jaar in de problemen komen als de prijzen, licentievoorwaarden of prestaties verschuiven. Abstractie lagen en multi-provider architecturen zijn aan te raden.
Bouw expertise op in plaats van te wachten. Bedrijven die nu met AI experimenteren - ook met Amerikaanse modellen - doen ervaring op die later niet gemakkelijk kan worden herhaald. De hamvraag is minder “welk model” en meer “welk proces heeft er baat bij”.”
Meer over praktische implementatie en een overzicht van concrete Europese alternatieven vind je hier
Conclusie
Het is onwaarschijnlijk dat Europa op korte termijn zijn eigen ChatGPT zal produceren. De redenen zijn structureel: kapitaal, infrastructuur, talentbehoud en marktfragmentatie werken op elkaar in en kunnen niet afzonderlijk worden opgelost. Europese initiatieven zoals Mistral of Aleph Alpha tonen aan dat het bouwen van eigen funderingsmodellen mogelijk is - maar met andere prioriteiten en marktpositionering dan ChatGPT.
Voor bedrijven betekent dit dat ze niet moeten wachten, maar soeverein gebruik moeten maken van bestaande modellen binnen Europese kaders. Met de juiste architectuur kunnen prestaties en compliance worden gecombineerd zonder afhankelijk te zijn van een Europees equivalent dat waarschijnlijk niet snel zal verschijnen.